
The amount of discoverable evidence companies generate has increased in recent years as departments across businesses have used new technology tools and remote work has become commonplace.
But AJ Shankar, founder and CEO of the ediscovery company Everlaw, likes to point out that in-house legal teams and their budgets have not grown at the same rate as the data. As a result, legal departments and their outside counsel face challenges in sorting through massive amounts of evidence to detect key information.
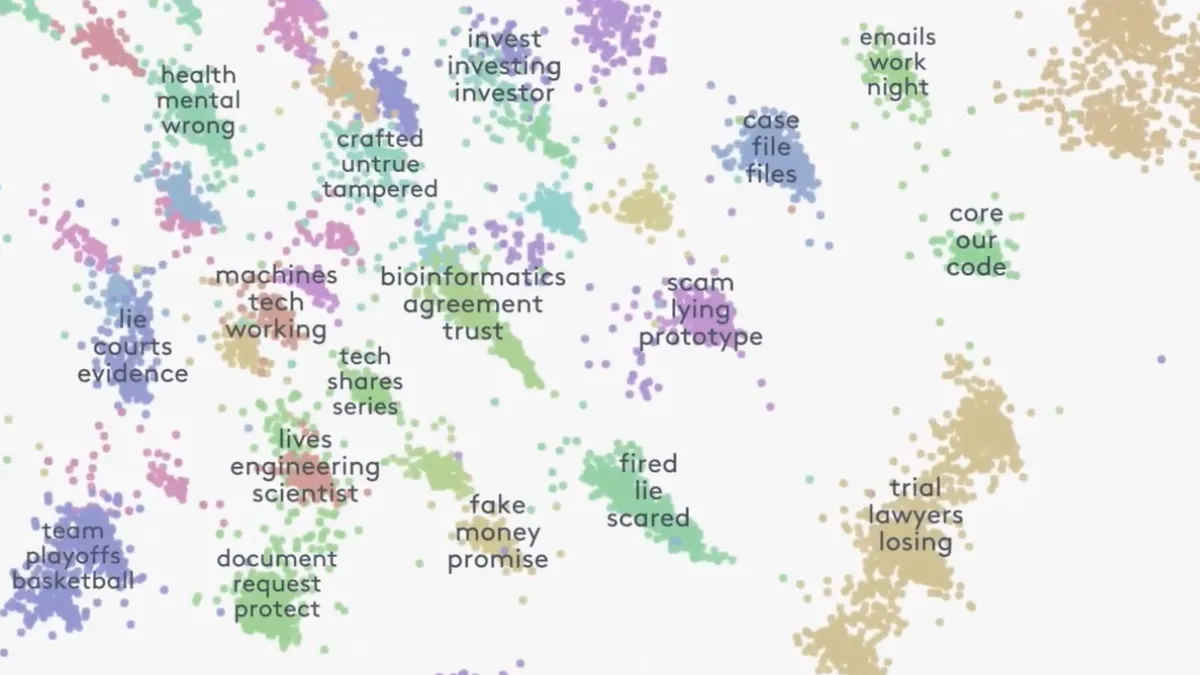
In hopes of helping legal teams and law firms more easily find needles in discovery haystacks, Everlaw has released for general availability its clustering feature following a test of the software by a range of different users.
The software uses AI to review all the documents in a case and then groups together similarly themed pieces of evidence in an easy-to-view fashion, according to Shankar.
“It lets you leverage just an incredible amount of insight in a really efficient way, which is what in-house teams care a ton about,” Shankar tells Legal Dive.
Dynamic visual experience
Other companies such as Logikcull and CloudNine offer clustering tools as part of their ediscovery platforms.
But Shankar says a major selling point of Everlaw’s clustering tool is its visual interface that starts by providing a 30,000-foot view of groups of conceptually related documents. The closer different clusters are to one another, the more connected those groupings of documents will be.
Users can zoom in and out on the clusters depending on criteria of interest to them, and they can get as granular as viewing individual documents that are displayed.
“For the end-user, it should feel like, ‘I'm in Google Maps,’ Shankar says. “I'm zooming in. I'm panning. I'm selecting stuff. I'm just intuitively exploring.”
He highlights that users “don't need any sophisticated understanding of how the AI works to use the tool.”
There is also information that can be laid over the initial clusters of documents the software produces. Shankar says one option is to overlay Everlaw’s existing predictive coding function that will identify clusters that are likely to include important documents.
Additionally, users can overlay manual ratings they have given to the clusters or specific documents to aid in their review of discovery.
Overall, the software supports up to 25 million documents on its single-screen clustering dashboard and is integrated with the Everlaw platform.
“I don't think there's any analog in the industry to what this is,” Shankar says.
Different case stages
Shankar says beta users have found Everlaw’s clustering tool to be helpful to legal teams and their outside counsel at a mix of case stages.
One example would be an early case assessment where a legal team is trying to estimate the budget for its review team, as well as potentially mark large swathes of discovery as either relevant or irrelevant.
The software could also help when a team is moving to the discovery review phase and determining which clusters it wants its first-line review team to focus on and which ones more sophisticated reviewers should comb through.
“You can use this during review to focus your efforts and plan your strategy,” Shankar says.
Additionally, users could turn to clustering when they are doing quality checks before producing discovery in a case. This could include making sure documents are properly categorized as privileged or confidential, as well as ensuring non-responsive information is not included in the discovery production.
And Shankar says much like other elements of Everlaw’s software, the clustering feature is designed for collaboration.
“This is consistent with our general MO for the platform, which is that in-house teams and outside counsel should be really fruitful and frequent collaborators with each other on these shared matters,” he says.






